Index Oluşturuken GROUP BY İfadesindeki Kolona Dikkat Etmek
Bu makaleyi okumaya başlamadan önce index’ler ile ilgili daha detaylı bilgi almak için “SQL Server’da Index Kavramı ve Performansa Etkisi” isimli makaleyi okumanızı tavsiye ederim.
Order By ifadesine konan index’in sorgudaki sort maliyetini sıfıra indirdiğini “Index Oluştururken Sorgudaki Order BY Yönüne Bakmak(ASC,DESC)” isimli makalemizde anlattım. GROUP BY ifadesinde belirtilen kolona koyulan index’te aynı şekilde sort maliyetini sıfıra indirger. Bir örnek yaparak bu işlemin nasıl olduğunu inceleyelim.
Öncelikle AdventureWorks veritabanında SalesOrderDetail tablosundaki Primary Key’in index’i haricindeki tüm index’leri silelim.
Daha sonra aşağıdaki sorgunun execution plan’ını alalım. Execution plan’ı almak için SSMS üzerinde sorgu ekranındayken aşağıdaki siyah kare içersine alınmış kısma tıklamanız gerekir. Execution plan hakkında detaylı bilgi almak için “Execution Plan Nedir” isimli makaleyi okumanızı tavsiye ederim.
SELECT ProductID, AVG(UnitPrice) AS 'Average Price', SUM(LineTotal) AS SubTotal FROM Sales.SalesOrderDetail WHERE SalesOrderDetailId=9 GROUP BY ProductID
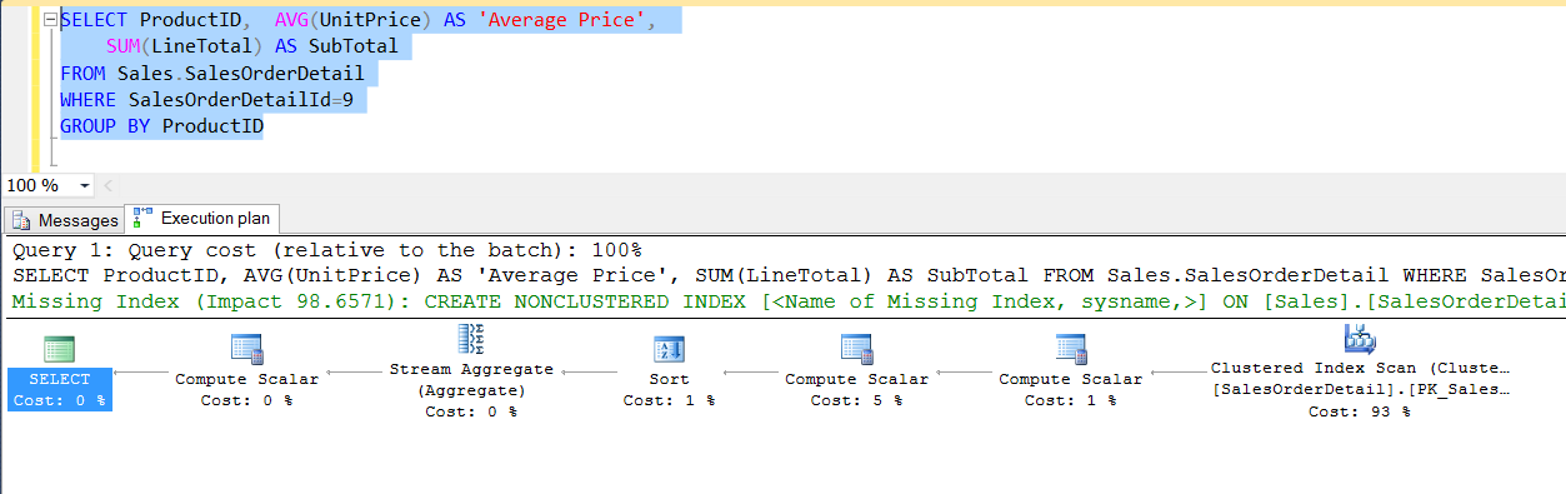
Gördüğünüz gibi Group By ifadesinden dolayı sorguda bir Sort maliyeti bulunuyor. Bizim sorgumuzda bu maliyet %1 olarak gözüküyor ama sizin sorgunuzda bu oran daha fazla olabilir.
Şimdi Group By ifadesindeki ProductID kolonuna aşağıdaki gibi bir index koyalım ve sorgunun execution plan’ını tekrar oluşturalım.
CREATE NONCLUSTERED INDEX [IX_ProductID] ON [Sales].[SalesOrderDetail] ( [ProductID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = ON, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
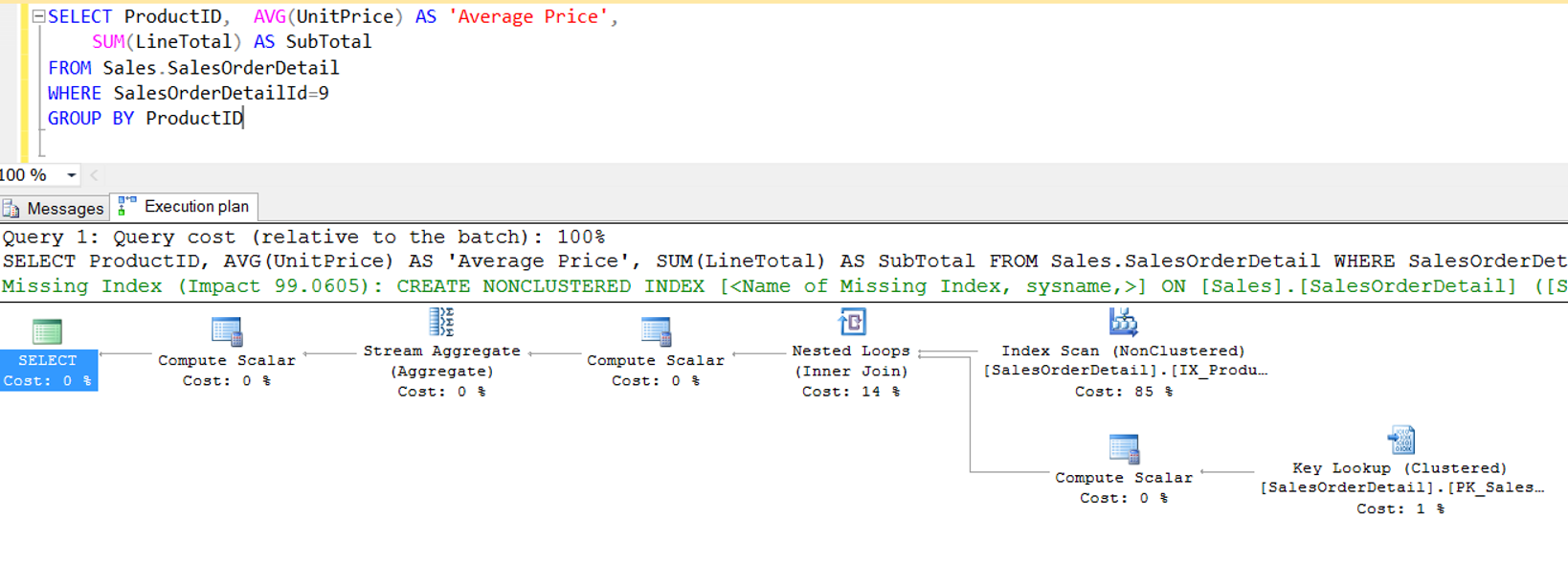
Gördüğünüz gibi sorgudaki sort maliyeti kayboldu.
![]()