Tablolarınızı Aktarırken Parallelism Kullanarak Daha Hızlı Aktarın((Parallel Insert Select))
SQL Server 2016 ile beraber artık INSERT INTO… SELECT ifadesini WITH(TABLOCK) ile kullanarak sorguda parallelism kullanabiliyoruz.
Sorgunun paralel çalışabilmesi için veritabanının compatibility level’inin en az 130 olması gerekiyor.
Compatibility Level’lerle ilgili “Compatibility Level Nedir Ve Nasıl Değiştirilir” isimli makaleyi okumak isteyebilirsiniz.
Bir örnek yaparak nasıl çalıştığını inceleyelim.
Öncelikle AdventureWorks veritabanında aşağıdaki gibi Person.Person tablosunun create script’ini aşağıdaki gibi alalım.
Daha sonra bu script’i kullanarak Person.Person2 ismiyle Person.Person tablosu ile aynı yapıya sahip bir tablo oluşturalım. Script’i çalıştırmadan tablo ve constraint isimlerini değiştirmeyi unutmayın yoksa aşağıdaki gibi hatalar alırsınız.
Msg 2714, Level 16, State 5, Line 27
There is already an object named ‘DF_Person_NameStyle’ in the database.
Msg 1750, Level 16, State 1, Line 27
Could not create constraint or index. See previous errors.
Çalıştıracağınız script aşağıdaki gibi olmalı.
USE [AdventureWorks2016CTP3] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [Person].[Person2]( [BusinessEntityID] [int] NOT NULL, [PersonType] [nchar](2) NOT NULL, [NameStyle] [dbo].[NameStyle] NOT NULL, [Title] [nvarchar](8) NULL, [FirstName] [dbo].[Name] NOT NULL, [MiddleName] [dbo].[Name] NULL, [LastName] [dbo].[Name] NOT NULL, [Suffix] [nvarchar](10) NULL, [EmailPromotion] [int] NOT NULL, [AdditionalContactInfo] [xml](CONTENT [Person].[AdditionalContactInfoSchemaCollection]) NULL, [Demographics] [xml](CONTENT [Person].[IndividualSurveySchemaCollection]) NULL, [rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL, [ModifiedDate] [datetime] NOT NULL, CONSTRAINT [PK_Person_BusinessEntityID_2] PRIMARY KEY CLUSTERED ( [BusinessEntityID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO ALTER TABLE [Person].[Person2] ADD CONSTRAINT [DF_Person_NameStyle2] DEFAULT ((0)) FOR [NameStyle] GO ALTER TABLE [Person].[Person2] ADD CONSTRAINT [DF_Person_EmailPromotion2] DEFAULT ((0)) FOR [EmailPromotion] GO ALTER TABLE [Person].[Person2] ADD CONSTRAINT [DF_Person_rowguid2] DEFAULT (newid()) FOR [rowguid] GO ALTER TABLE [Person].[Person2] ADD CONSTRAINT [DF_Person_ModifiedDate2] DEFAULT (getdate()) FOR [ModifiedDate] GO ALTER TABLE [Person].[Person2] WITH CHECK ADD CONSTRAINT [FK_Person_BusinessEntity_BusinessEntityID2] FOREIGN KEY([BusinessEntityID]) REFERENCES [Person].[BusinessEntity] ([BusinessEntityID]) GO ALTER TABLE [Person].[Person2] CHECK CONSTRAINT [FK_Person_BusinessEntity_BusinessEntityID2] GO ALTER TABLE [Person].[Person2] WITH CHECK ADD CONSTRAINT [CK_Person_EmailPromotion2] CHECK (([EmailPromotion]>=(0) AND [EmailPromotion]<=(2))) GO ALTER TABLE [Person].[Person2] CHECK CONSTRAINT [CK_Person_EmailPromotion2] GO ALTER TABLE [Person].[Person2] WITH CHECK ADD CONSTRAINT [CK_Person_PersonType2] CHECK (([PersonType] IS NULL OR (upper([PersonType])='GC' OR upper([PersonType])='SP' OR upper([PersonType])='EM' OR upper([PersonType])='IN' OR upper([PersonType])='VC' OR upper([PersonType])='SC'))) GO ALTER TABLE [Person].[Person2] CHECK CONSTRAINT [CK_Person_PersonType2] GO
Tabloyu oluşturduktan sonra Person2 tablosundaki Primary Key’i kaldırıyoruz ve aşağıdaki script yardımıyla insert into cümleciğimizi çalıştırıyoruz.
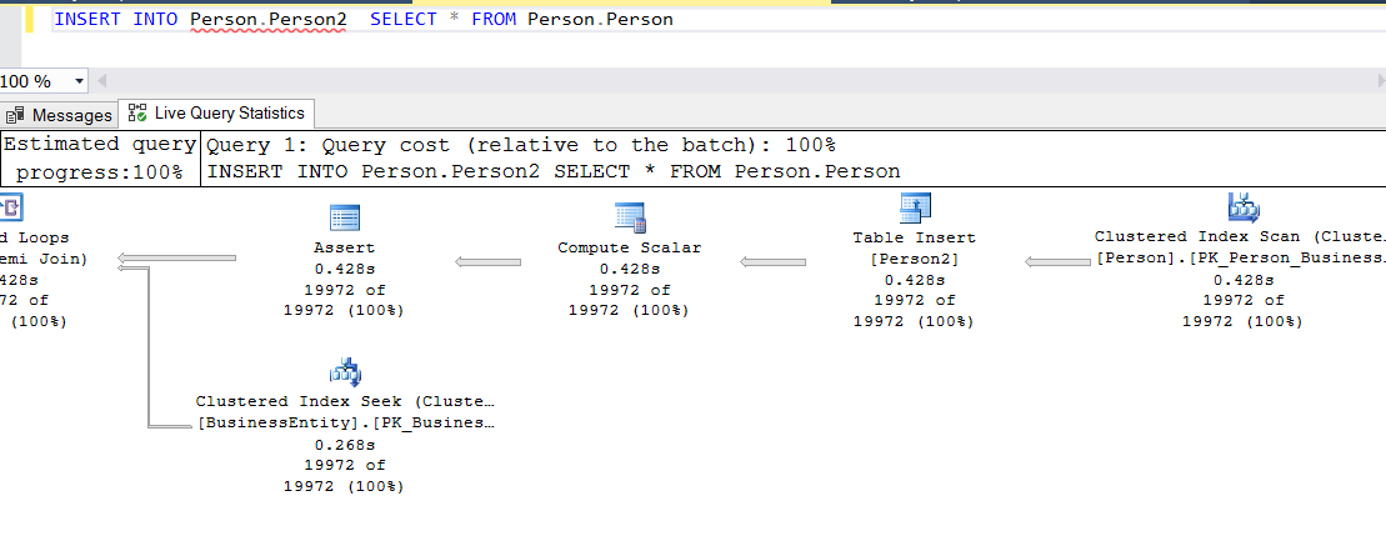
INSERT INTO Person.Person2 SELECT * FROM Person.Person
Execution plan’a baktığımızda aşağıdaki gibi Clustered Index Scan ve Table Insert işlemlerinin parallelism olmadan gerçekleştiğini görüyoruz.
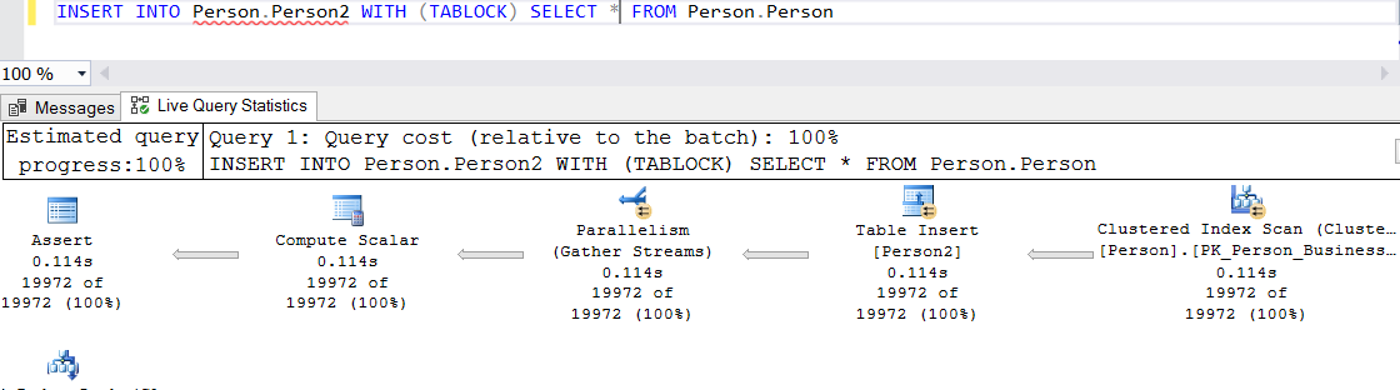
INSERT INTO cümleciğini WITH(TABLOCK) ile aşağıdaki şekilde çalıştıralım ve execution plan’a tekrar bakalım.
Gördüğünüz gibi sorgu bu sefer parallelism kullanarak çalıştı.
![]()