DBCC SHOW_STATISTICS Nedir ve Nasıl Kullanılır
DBCC SHOW_STATISTICS ile bir istatistik hakkında detaylı bir bilgi alabiliriz. Çoğunuzun bildiği gibi istatistikler query plan oluşturulurken sql server engine’in karar vermesindeki en önemli rollerden birine sahiptir. SQL Server Engine istatistiklere bakılarak bir index’in kullanılıp kullanılmayacağına ya da ne şekilde kullanılacağına karar verir. Bu yüzden herşeyden önce istatistiklerimizin güncel olması gerekir.
Bu makaleyi okumadan önce bu komuta neden ihtiyacınız olduğunu daha iyi anlamak için aşağıdaki makaleleri okumanızı tavsiye ederim.
“SQL Server’da İstatistik Kavramı ve Performansa Etkisi“,
“SQL Server’da Index Kavramı ve Performansa Etkisi“,
DBCC SHOW_STATISTICS bir tablo’daki veya indexed view’deki bir istatistik hakkında detaylı bilgileri gösterir.
Bu komutun çıktısı 3 öğeden oluşur.
- Statistic Header
- Density Vector
- Histogram
Bir örnek üzerinden yukardaki kavramları ve detaylarını açıklayalım. AdventureWorks veritabanında aşağıdaki komutu çalıştırın.
Bu komutta,
HumanReources şema adını,
Department tablo adını,
AK_Department_Name’de istatistik adını belirtiyor.
DBCC SHOW_STATISTICS([HumanResources.Department],[AK_Department_Name])
Karşımıza aşağıdaki gibi bir sonuç kümesi çıkıyor.
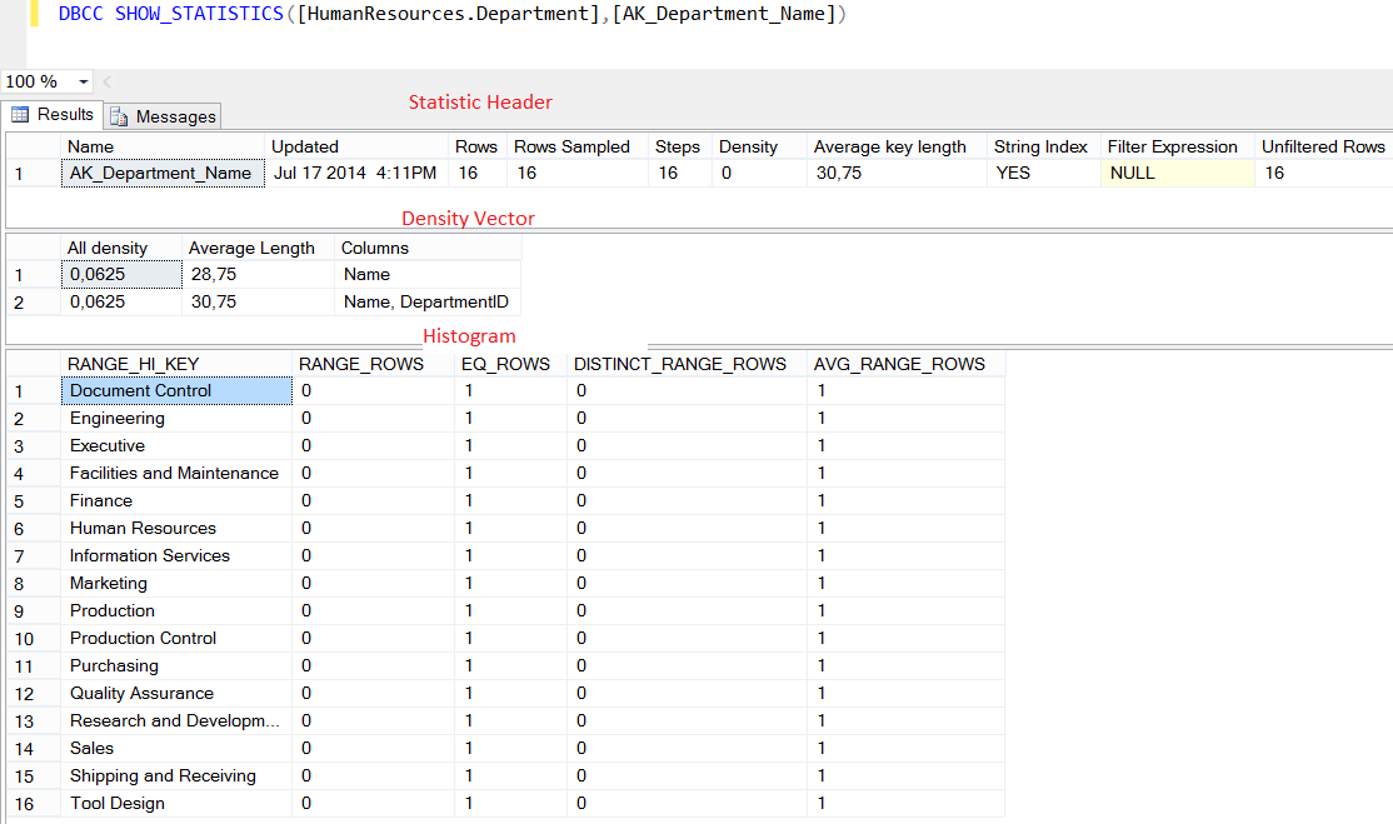
Aşağıdaki tablolarda sonuç kümesinde gelen kolonların açıklamalarını görebilirsiniz.
|
Statistic Header |
|
|
Name |
İstatistik ismi |
|
Updated |
İstatistiğin son update edildiği tarih |
|
Rows |
İstatistik son update edildiğinde bağlı olduğu tablo ya da indexed view üzerindeki satır sayısını gösterir. |
|
Rows Sampled |
İstatistiği oluştururken ya da güncellerken örnek alınan satır sayısıdır. “UPDATE STATISTICS Nedir” isimli makalede daha detaylı bilgi bulabilirsiniz. |
|
Step |
Histogram’daki step sayısını belirtir. Histogram kısmında değineceğiz. |
|
Density |
SQL Server 2008’den sonraki sürümlerden sonra kullanılmamıştır. |
|
Average Key Length |
İstatistiği oluşturan kolonların byte cinsinden ortalama büyüklük değeri |
|
String Index |
Eğer istatistiği oluşturan kolonlar char, varchar, nchar, nvarchar, varchar(max), nvarchar(max), text, veya ntext kolonlarından biriyse bu kolon YES değerini alır. |
|
Filter Expression |
Eğer istatistik filtrelenmişse filtre ifadesini gösterir. |
|
Unfiltered Rows |
Filtrelenmemiş satır sayısını gösterir. Eğer filtre yoksa istatistiğin bağlı olduğu tablo ya da indexed view’deki satır sayısını verecektir. |
|
Density Vector |
|
|
All Density |
1/n değerini ifade eder. Buradaki en tablodaki birbirinden farklı kayıt sayısıdır. Bu satır 0’a ne kadar yakında tekillik o kadar sağlanmış demektir. |
|
Average Length |
İstatistiği oluşturan kolonların byte cinsinden ortalama büyüklük değeri |
|
Columns |
Bir önceki iki kolondaki All Density ve Average Length’in hangi kolonlar için hesaplandığını gösterir. |
|
Histogram |
Veri dağılımını gösteren grafik. SQL Server bir istatistiği oluştururken öncelikle kolon değerlerini sıralar. Sonrasında verileri belirli gruplara ayırır ve her grubun üst sınırını belirler. Örneğin 1’den 1000’e kadar değeri olan bir kolon olduğunu düşünün. Bu kolonda istatistik oluşurken veriler gruplandı ve 100’e bölündü. Bu 100 parça’nında 1’den 10’a kadar, 10’dan 20’ye kadar şeklinde ayrıldığını varsayalım. Burada 1’den 10’a kadar olan kısım 1 step olarak geçer. 100’e bölündüğü içinde bu istatistiğin histogramında 100 step var demektir. |
|
RANGE_HI_KEY |
Histogram step’i için üst sınırı belirten key değeri. Yani verilerin dağılımında her step’i birbirinden ayıran bir çizgi. |
|
RANGE ROWS |
Bir histogram adımı(step) başına düşen tahmini satır sayısı |
|
EQ_ROWS |
Bir üst sınır’a eşit olan kayıt sayısı |
|
DISTINCT_RANGE_ROWS |
Bir histogram adımı(step) başına düşen tahmini duplike olmayan satır sayısı |
|
AVG_RANGE_ROWS |
İlgili stepteki(histogramdaki satır) duplike kayıt sayısı |
![]()