ColumnStore Index Nedir ve Nasıl Kullanılır?
ColumnStore Index SQL Server 2012 ile beraber hayatımıza girdi. Kolon bazlı indexleme diyebiliriz. Normalde index yapısı satır bazlı tutulur ve bu satırlar bir araya getirilerek index oluşturulur. ColumnStore Index’te ise kolonlar bir araya getirilerek index oluşturulur. Genelde datawarehouse için kullanılıyor. Microsoft’a göre datawarehouse sorguları için 10 kata kadar performans artışı ve 7 kata kadar sıkıştırma yapabiliyor.
İlk etapta columnstore index’in sql server 2012’deki özelliklerinden bahsederek başlayağım ve daha sonra SQL Server 2014 ve 2016’da gelen yenilikleri anlatarak devam edeceğim.
SQL Server 2012 ile beraber,
NonClustered ColumnStore index oluşturabiliyoruz.
ColumnStore Index veriyi kolon bazlı tuttuğu için sadece ihtiyaç duyulan kolonları okuyarak okunan veri miktarını azaltarak performans sağlar.
Kolonlar sıkıştırılmış olarak tutulurlar ve bu şekilde de okunan veri miktarı azalır ve performans artışı sağlanır.
Veri az okunduğu için diskten memory’e aktarılan veri de az olur ve bu şekilde memory de çok efektik bir şekilde kullanılır.
ColumStoreIndex koyduğumuzda tablonun boyutu da ciddi anlamda küçülecektir. Makalenin ilerleyen bölümlerinde bir örnek yaparak ne kadar küçüleceğini göreceğiz.
ColumStore Index olan bir tabloda bir sorgu çalıştırıldığında özel bir query execution teknolojisi çalışır ve cpu kullanımını azaltır.
Clustered Index olan bir tabloda ColumnStore Index oluşturmak isterseniz Clustered Index’in bütün kolonları ColumnStoreIndex’te olmalıdır. Eğer create script’ine koymazsanız otomatik olarak sql server bu kolonları columnstore index’e ekleyecektir.
Partition ile beraber kullanılabilir, ama partition kolonunun columnstore index üzerinde tanımlı olması gerekir.
Normal index’lerin 900 byte’ı geçmemesi gerekirdi. ColumnStore index’te böyle bir sınırlama yok.
Bu index yapısı SQL Server 2012’de çok kullanılmadı. Çünkü columnstore index olan bir tablo update edilemiyordu. Update edilmesi gerektiğinde recreate işlemi yapılıyordu. Buna rağmen hızlı bir şekilde toplu rapor alma amacıyla kullanılabilirdi.
Aşağıdaki script yardımıyla clustered index’i olan örnek bir tablo oluşturalım ve içine rasgele kayıt ekleyelim.
CREATE TABLE ColumnStoreOrnek (ID [int] NOT NULL, SehirID [int] NOT NULL, UlkeID [int] NOT NULL, SehirIsmi char(100) NOT NULL, UlkeIsmi char(100)); GO CREATE CLUSTERED INDEX CIX_ID ON ColumnStoreOrnek (ID); GO DECLARE @sayac bigint; SET @sayac=0 while(1=1) BEGIN INSERT INTO [dbo].[ColumnStoreOrnek]([ID],[SehirID],[UlkeID],[SehirIsmi],[UlkeIsmi]) VALUES (@sayac,@sayac,@sayac,'ulke','ulke') SET @sayac=@sayac+1 END
Yukarıdaki script’i tablo boyutu 1 GB olana kadar çalıştırın. Sorgu çalışmaya devam ederken aşağıdaki script yardımıyla tablonun boyutundaki ilerlemeyi kontrol edebilirsiniz.
exec sp_spaceused 'ColumnStoreOrnek'
Benim yaptığım örnekte tablo boyutu aşağıdaki gibi(reserved ve data alanında görebilirsiniz) yaklaşık 100 mb olduğunda ben script’i durdurdum.
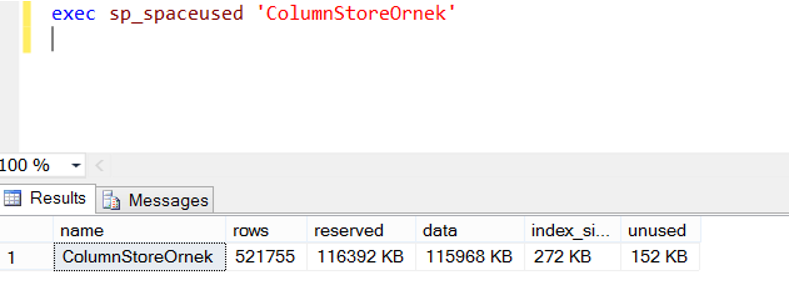
ColumnStore Index oluşturmadan önce normal index performansına bakmak için SehirID kolonunda aşağıdaki gibi bir index oluşturalım. Index script’inde WITH(ONLINE=ON,MAXDOP=4) hintini göreceksiniz. ONLINE=ON diyerek bu index oluşturma işleminin uygulamayı locklamasını engellemiş oluyorum. MAXDOP=4 ile de sorgunun daha fazla cpu kullanarak çalışmasını sağlamış oluyorum. Tabi burada 4 yazdım ama belki sunucunuzda 4 core yok daha fazlası var. Örneğin 64 core’unuz var ve 8 numa node’unuz var. MAXDOP=8 ya da MAXDOP=16 diyebilirsiniz. Numa Node sayısı ile ilgili “Numa Nodes, MAX/MIN Server Memory, Lock Pages In Memory, MAXDOP” isimli makalemi okumak isteyebilirsiniz.
CREATE NONCLUSTERED INDEX [IX_Index] ON [dbo].[ColumnStoreOrnek] ( [SehirID] ASC ,[UlkeID] ASC ,[SehirIsmi] ASC ,[UlkeIsmi] ASC )WITH (ONLINE = ON,MAXDOP=4)
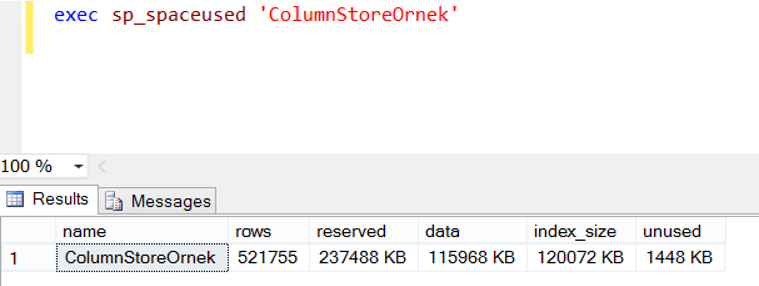
Index’i oluşturduktan sonra exec sp_spaceused ‘ColumnStoreOrnek’ script’ini tekrar çalıştırıyorum ve index size’ın 120 mb arttığını görüyorum. Tabi eş zamanlı olarak tablo boyutu da arttı.
Şimdi birde nonclustered columnstore index oluşturalım.
CREATE NONCLUSTERED COLUMNSTORE INDEX ColumnStoreIndexOrnek ON ColumnStoreOrnek (SehirID ,UlkeID ,SehirIsmi ,UlkeIsmi) WITH(MAXDOP=4); GO
Non clustered columnstore index’i oluşturduktan sonra exec sp_spaceused ‘ColumnStoreOrnek’ script’ini tekrar çalıştırıyorum ve index size’ın 4 mb arttığını görüyorum. Normal index’e göre columnstore index’in kullandığı alan 30 kat azaldı.
Aşağıdaki iki script yardımıyla hem normal nonclustered index’i hem de nonclustered columnstore index’i kullanarak ne kadar IO yaptığımızı ve sorguların cpu’yu ne kadar kullandığını görecek şekilde bir sorgu çalıştıralım.
SET STATISTICS IO,TIME ON SELECT * FROM [Test].[dbo].[ColumnStoreOrnek] WITH(Index=IX_Index) where SehirID<1000000 SET STATISTICS IO,TIME ON SELECT * FROM [Test].[dbo].[ColumnStoreOrnek] WITH(Index=ColumnStoreIndexOrnek) where SehirID<1000000
Sorgu sonucunda messages kısmına baktığımızda normal nonclustered index’in yaptığı IO’nun çok daha fazla olduğunu ve cpu süresinin de daha fazla olduğunu görebilirsiniz.

Yukarıdaki ekran görüntüsüne baktığımızda normal nonclustered index 14493 logical read yaparken, nonclustered columnstore index 1091 lob logical read yapmış.
Şimdi birde SehirID<1000000 değerinden birkaç 0 atın ve sorguyu tekrar çalıştırın. Aşağıda göreceğiniz gibi normal index’in yaptığı IO azaldı ama columnstore index’in yaptığı IO azalmadı.

Bu testlere dayanarak küçük verilerle çalışırken normal index daha performanslı çalışıyorken, büyük verilerle çalıştığımızda nonclustered columnstore index daha performanslı çalışıyor. SQL Server Execution plan’ı üretirken maliyeti hesaplar ve en uygun’u hangi yol ise o yoldan gider.
Şimdi yukardaki select sorgularından force index hintini kaldıralım ve sorgunun hangi index’i kullanacağını sql server’a bırakalım.
Aşağıda gördüğünüz gibi Where SehirID<100 iken normal nonclustered index’i kullandı.
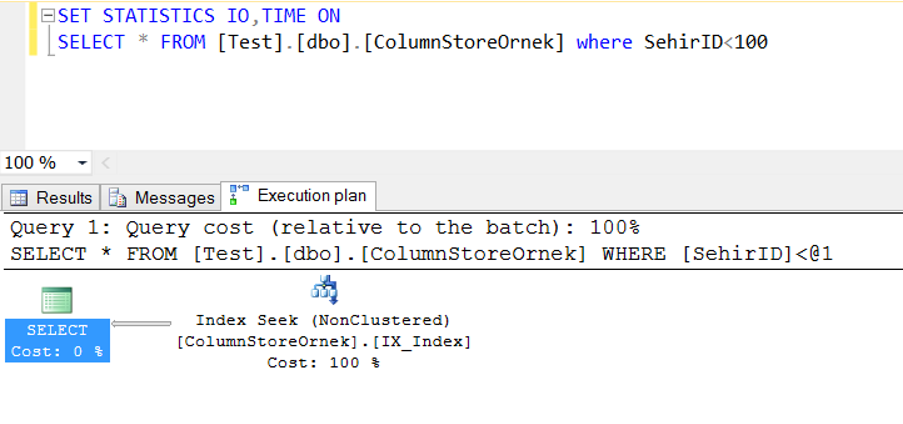
Şimdi ise Where SehirID<100000 yaparak sql server’ın hangi execution plan’ı kullanacağına bakalım.
Gördüğünüz gibi columnstore index’i kullandı.

Peki SQL Server 2012’de columnstore index’in kısıtlamaları nelerdir?
- Sadece nonclustered columnstore index oluşturulabiliyor. Clustered columnstore index sql server 2012’de yok.
- 1024 kolondan fazlasına oluşturulamıyor ama kimsenin bu kadar kolon üzerinde columnstore index oluşturacağını sanmıyorum.
- Unique olarak oluşturulamıyor.
- View ya da indexed view’de oluşturulamıyor.
- Sparse kolon içeremez.
- Tabloda primary key tanımlayabilirsiniz ama columnstore index aynı zamanda PrimaryKey ve ForeingKey olamaz.
- ALTER INDEX yapılamaz. ALTER yapmak istediğinizde DROP-CREATE yapmanız gerekir.
- INCLUDE olarak kolon eklenemez. “SQL Server’da Index Kavramı ve Performansa Etkisi” isimli makalemde include kolon’un detaylarını bulabilirsiniz.
- Kolonlar asc ya da dsc olarak sıralanamazlar. Columstore index sıkıştırma algoritmasına göre sıralanır.
- FileStream özelliği içeremez.
- Index seek desteklemez. Bu yüzden küçük veri kümeleri çekilecekse sql server columnstore index kullanmayı tercih etmez. Yukarda örneğini yapmıştık.
- En önemlisi sql server 2012’de nonclustered columstore index tanımladıysanız bu tablo update edilemez. 🙂
Columnstore index aşağıdakilerle birlikte kullanılamaz.
- Page ve Row Compression
- Replication
- Change tracking
- Change data capture
- Filestream
SQL Server 2014 ile beraber update edilebilir clustered columstore index hayatımıza girdi. Tabloda bu şekilde clustered columnstore index koyduğumuzda başka hiçbir index koyamıyoruz. Silme işlemleri sadece silindi olarak işaretlenerek daha sonra arka planda silinirler ve bu yüzden silme performansı çok hızlıdır.
Tabloyu daha da küçültebileceğimiz compression metodu olarak columnstore_archieve geldi. Aşağıdaki script yardımıyla bu işlemi gerçekleştirebiliriz.
ALTER TABLE [dbo].[ColumnStoreOrnek]
REBUILD WITH (DATA_COMPRESSION=COLUMNSTORE_ARCHIVE)
SQL Server 2016 ile beraber;
- Isolation Level seviyelerinde değişiklik geldi. Snapshot Isolation ve Read Committed Snapshot Isolation Level’leri kullanabiliyoruz. Isolation Level’ler ile ilgili aşağıdaki makalelerimi okuyabilirsiniz.
- Always on’daki read edilebilir secondary, update edilebilir columnstore index’i destekliyor.
- Clustered columnstore index olan bir tabloda btree index oluşturulabiliyor.
- Memory-Optimized Table’da column store index oluşturulabiliyor.
- Nonclustered columnstore index filtered olabiliyor.
- Tablo oluşturulurken columnstore index oluşturulabiliyor.
![]()