Veritabanı file group yapısı ve büyük tablolarımızı başka bir file group’ta yeniden oluşturmak
Bu makalede veritabanı ilk oluşturulduğunda, ya da başka bir ortamdan geldiğinde file group yapısını düzenlerken nelere dikkat etmemiz gerektiğinden ve tablolarımızı başka bir file group’a neden ve nasıl aktaracağımızdan bahsedeceğim.
Bir tabloyu neden başka bir filegroup’ta oluşturmak gerekebileceğinden bahsedelim. Veritabanı başka bir ortamdan gelmiş, tek mdf file üzerinde oluşturulmuş ve çok büyüdüğü için IO beklemesi artmış olabilir. Bu durumda yeni bir filegroup oluşturup bu oluşturduğunuz file group içinde, veri büyüklüğü ve mevcut disk sayısına göre file yaratıp, büyük tablolarınızı yeni filegroup’a aktararak tablonuzu disklere eşit bir şekilde yayabilirsiniz. Bu işlemi var olan disk sisteminizi alt katmanda parçalara bölerekte gerçekleştirebilirsiniz. Bunu sistem grubundaki arkadaşlarınızla beraber planlayabilirsiniz. Tabi büyük tabloların hepsinin tek file üzerinde kalmasının bazı sakıncalarıda olabilir. Mesela 10 TB boyutu olan bir veritabanı içersinde 3 tane büyük tablo olduğunu düşünelim. A tablosu 3 TB, B tablosu 2 TB, C tablosu 1 TB olsun. Eğer bütün bu tablolar aynı file group üzerinde olursa backup almakta sıkıntı yaşayabilirsiniz. Ama her tablo farklı file group üzerinde olursa file group backup alarak bu sıkıntıyı aşabilirsiniz.
Ayrıca büyük veritabanlarında bütün data’nın mdf file üzerinde olması, sistem objeleride mdf file üzerinde olduğu için tavsiye edilmez. Sadece mdf file üzerinde büyümüş büyük bir veritabanında,eğer indexleriniz ayrı bir file group üzerinde değilse fragmente olmuş index sorgusunu çektiğinizde bile cevap alamayabilirsiniz. Bu durumda ihtiyaca göre mdf file üzerindeki tablolar yeni file group’lara dağıtılmalıdır. İlk tasarım aşamasında eğer veritabanının büyüyeceği biliniyorsa(ben 500 GB’ı geçecek veritabanların da bu yöntemi izliyorum) PRIMARY file group yerine yeni bir file group oluşturup bu file group’u default olarak seçmek daha avantajlıdır. Veritabanının ve oluşacak tabloların büyüklüğüne göre file group sayısını ve file sayılarını belirleyebilirsiniz. Indexlerinizin daha performanslı çalışması için indexlerinde ayrı bir file group üzerinde oluşturulmasında fayda var. Index büyüklüğüne göre file sayısını belirleyebilirsiniz.
Tablolarınızı yeni bir file group’a taşımanızın bir nedenide var olan file group’ta verilerin file’lara düzensiz dağılmış olması olabilir. İlk başta tek file ile başlanmış ve veri büyüklüğü arttıkça yeni file’lar eklenmişse tablolar file’lara düzensiz dağılacaktır. Clustered Index Rebuild işlemi bu sıkıntıyı bir nebze çözsede hiçbir zaman tam olarak çözmeyecektir. Çünkü clustered index rebuild işleminde, engine önce tablonun kaç tane file üzerinde yayılmış olduğunu görür. Daha sonra bu file’ların büyüklüklerine ve içlerindeki bulundukları boş miktara bakar. Ve her seferinde hangi file’ın içersinde daha fazla boş miktar varsa o file’ın içine daha fazla veri yazar. Bu şekilde her rebuild işlemi sonrasında boş olan file daha dolu olacak ve dolu olan file daha boş olacaktır. Bu yüzden yeni bir file group yaratıp tabloyu buraya taşımak daha mantıklı bir yol olacaktır.
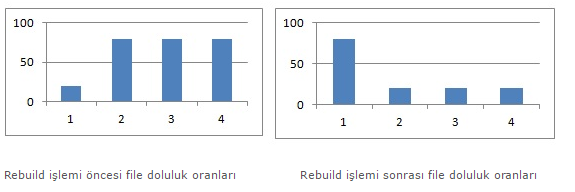
Tabloyu yeni bir file group’a taşımak ile ilgili 3 durumdan bahsedeceğim.
1. Şimdi boyutu çok büyük olmayan ve içersinde lob data olmayan bir tablo yeni bir file group’a nasıl taşınır onu inceleyelim. Bu işlemi aşağıdaki şekilde gerçekleştirebiliriz.
CREATE UNIQUE CLUSTERED INDEX PK_XXX on dbo.Table_XXX (Column_XXX) with (DROP_EXISTING=ON) on [NEW FILEGROUP] GO
Not: İlerde bu tabloda lob data veri olma ihtimali varsa 2.yöntemi izlemelisiniz.Aksi takdirde lob data veriler tabloyu taşıdığınız yeni filegroup’ta değilde eski file group altında konumlanır. Çünkü işlemi bu şekilde gerçekleştirdiğimizde tablonun desing’ındaki Text/Image File Group, Primary olarak kalacaktır.
2. Tablomuzun boyutu büyük ve içersinde lob data veri varsa ve loglama işlemleri için diskimizin yeterli olduğu bir durumda bir tabloyu yeni file group üzerinde aşağıdaki yöntemle oluşturarak bu işlemi gerçekleştirebilirsiniz.
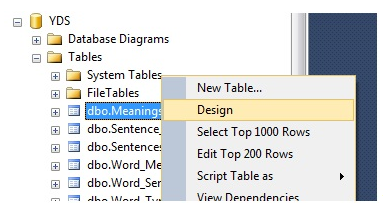
Tablo üzerinde sağ tıklayıp design’ı seçiyoruz.
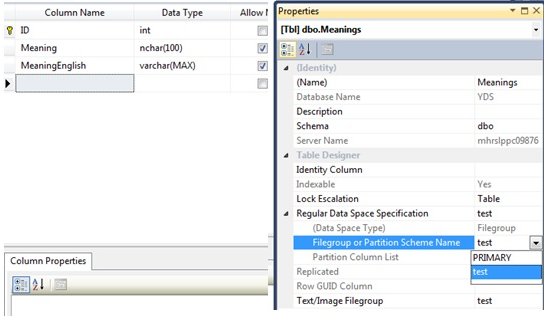
Tablo design görünümündeyken her hangi bir kolona tıklayıp properties penceresinden önce Regular Data Space Specification sekmesini açıyor ve Filegroup or Partition Scheme Name kısmından yeni file group’u seçiyoruz. Daha sonra Text/Image Filegroup üzerinde de aynı işlemi yapıyoruz.
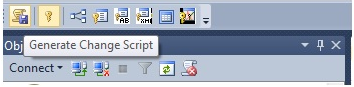
Properties’den ilgili yerlerde yeni file group’u seçtikten sonra tekrar herhangi bir kolon üzerine tıklayıp Generate Change Script’e tıklıyoruz.
Not: Generate Chance Script seçeneğini kullanabilmeniz için SQL Server Management Studio üzerinden Tools->Options->Designers ‘a gelip Prevent Saving Changes that require table re-creation checkbox’ındaki işareti kaldırmanız gerekiyor.
Script’imizi yukarıdaki şekilde kopyaladıktan sonra No diyerek ekranı kapatıyoruz ve scriptimizi yeni bir query olarak çalıştırıyoruz. Görüldüğü gibi tablomuzda LOB DATA veri olduğu için bu işlemi tabloyu re-create işlemi yaparak gerçekleştirebildik. Eğer tablomuzda LOB DATA verimiz olmasaydı sadece 1.yöntemi kullanarak taşıma işlemini gerçekleştirebilecektik.
3. 2.Durumda, görüldüğü gibi tablomuzun aynısı Tmp_XXX şeklinde yeniden yaratılıyor ve tek insert ile tüm tablo bu Tmp_XXX tablosuna aktarılıyor. Bu durumda tablomuz çok büyük olduğunda, bu log file için ayrıca bir disk ihtiyacı demektir. Recovery Mode’u simple’a çeksek bile tek insert işlemi olduğu için log büyümeye devam edecektir. Bu durumda recovery mode’u simple’a çekip aşağıdaki adımları izleyebiliriz.
2.Durumda yapılan işlemleri tekrarlayıp generate change script ile scriptimizi aldığımızda,
CREATE TABLE dbo.Tmp_ ile başlayan ifadeden önce bir transaction başlatılıyor. Bu transaction kapatılmadan CREATE TABLE dbo.Tmp_ işlemi, insert işlemi ve sonrasında bazı nesne yaratma işlemleri yapılıyor. İnsert işleminin tamamının bir transaction içersinde olmaması için CREATE TABLE dbo.Tmp_ ifadesinden önce bu transaction’ı COMMIT ile sonlandırmanız gerekiyor. Tabi bu durumda sorgunun ilk halinde transaction’ın commit olduğu yeri bulup buradaki COMMIT ifadesininde kaldırılması gerekir.
Daha sonra normal sorguda aşağıdaki gibi yapılan insert işlemini silmeniz gerekiyor.
IF EXISTS(SELECT * FROM dbo.XXX)
EXEC('INSERT INTO dbo.Tmp_XXX (Tabloda bulunan kolonlar)
SELECT Tabloda bulunan kolonlar FROM dbo.XXX WITH (HOLDLOCK TABLOCKX)')
Sildiğimiz bu sorgunun yerini aşağıdaki gibi dolduruyoruz.
CREATE TABLE #movedrows (RowID Primary Key Tipi primary key)
--Tablonun Primary Key tipi neyse burda RowID’nin tipini o şekilde veriyoruz.
DECLARE @RowCount int
SET @RowCount = 10000
--Tablonuzun yapısına göre buradaki sayıyı artırıp azaltmak gerekir.
--Örneğin Tablonuz 1 TB ve satır sayınız 100000 ise bu değeri 10000’den daha küçük bir --değer olarak set edebilirsiniz. Burda verdiğiniz değere göre işlem süreniz azalacak
--veya artacaktır. En optimum süreyi belirleyebilmek için tablonuzun büyüklüğüne ve
--satır sayısına bakarak karar vermeniz gerekecektir. Tabi bu işlemleri önce test
--ortamında yapmalısınız.
WHILE @RowCount > 0
BEGIN
SET IDENTITY_INSERT dbo.Tmp_XXX ON
INSERT INTO dbo.Tmp_XXX
(Tablodaki Tüm Kolonlar)
OUTPUT inserted.Primary Key INTO #movedrows
--Burada Primary Key yazan yere Primary Key kolonunuzun ismini yazmalısınız.
--Insert edilmiş satırların Primary Key kolonu #movedrows tablosuna aktarılıyor.
SELECT TOP 10000 Tablodaki Tüm Kolonlar
FROM dbo.XXX
WHERE NOT EXISTS (SELECT 1 FROM #movedrows WHERE RowID = Primary Key)
--Primary Key yazan yere Primary Key kolonunuzun ismini yazmalısınız.
--Burdada #movedrows tablosunda olmayan 10000 satır çekiliyor.
SET @RowCount = @@ROWCOUNT
SET IDENTITY_INSERT dbo.Tmp_XXX OFF
END
DROP TABLE #movedrows
Yukarıdaki sorguda BEGIN ifadesinden sonra SET IDENTITY_INSERT dbo.Tmp_XXX ON cümleciği,
SET @RowCount = @@ROWCOUNT ifadesinden sonrada SET IDENTITY_INSERT dbo.Tmp_XXX OFF
cümleciği kullanılmış. Eğer sizin tablonuzda identitiy değer yoksa bu ifade sorgunuzun ilk halinde de olmayacaktır. Dolayısıyla yukarıdaki sorguyu eklemeden önce bu ifadeleri kaldırmalısınız. Eğer tablonuzda identitiy değer varsa yukarıdaki sorgunun içersinde de olduğu için sorgunuzun ilk halindeki SET IDENTITY_INSERT dbo.Tmp_XXX ON ve SETIDENTITY_INSERT dbo.Tmp_XXX OFF cümleciklerini bulup kaldırmanız gerekecek.
Yukarıdaki sorguyla bütün tabloyu tek bir transaction’ın içersinde tek bir insert ile değilde belirlediğiniz sayıda satır insert ederek log file’ın büyümesini engellemiş olacaksınız.
![]()