Veritabanı Oluşturmak Deyip Geçmeyin!
Her şeyden önce veritabanı default olarak iki dosyaya sahiptir.
Bunlar mdf uzantılı data dosyası(Primary Data File olarak geçer) ve ldf uzantılı transaction log dosyalarıdır.
ndf uzantılı opsiyonel olan üçüncü bir dosya tipi daha vardır. Secondary Data file olarak geçer. mdf uzantılı data dosyasının dışında başka bir data file tanımlarsanız uzantısı ndf olacaktır.
Primary Data File’da veritabanı için başlangıç bilgisi ve veritabanı içindeki diğer file’lara ait bilgiler tutulur. Örneğin attach işlemi yaparken sadece mdf file’ı seçmeniz durumunda sql server diğer file’ları otomatik olarak getirecektir. Veritabanı file(dosya)’larının disklerini değiştirmek isimli makalemde detach attach işlemlerinin detaylarını bulabilirsiniz.
Eğer secondary bir data file tanımlamazsanız bütün veri Primary Data File içersinde tutulacaktır.
Primary Data File default file group olan PRIMARY File Group içersinde yer alır. Bütün sistem tabloları da PRIMARY file group altındadır.
PRIMARY File Group dışında başka bir File Group oluşturmazsanız, oluşturacağınız secondary data file’lar otomatik olarak PRIMARY file group altında oluşacaktır.
Anlaşılacağı üzere her data file bir file group altında olmak zorundadır. File Group’un amacı işletim sisteminden alan tahsis etmek, yönetim, ve file’ları gruplamak için kullanılır.
Detayları makalenin ilerleyen bölümlerinde anlatacağım.
Veritabanı oluşturmadan önce veritabanı isteğini yapan uygulamacı veya 3. diğer şahıslara aşağıdaki soruları sormamız gerekir.
Veritabanı Adı:
Veritabanı Collation Bilgisi:
2 yıl sonraki tahmini büyüklüğü:
Kaç kişinin kullanacağı:
Collation’ı belirleyerek verinin nasıl sıralanacağını ve karşılaştırılacağını belirlemiş olursunuz. Örneğin a harfinin A harfi ile aynı anlama gelip gelmediğini.
Uygulamaların bir çoğu Turkish_CI_AS ile sorunsuz bir şekilde çalışmaktadır. Ama bazı paket programların oluşturduğu veritabanları farklı collation yapıları ile çalışabilmektedir. Bu yüzden veritabanı talebi yapan kişiden bu bilgiyi istemeniz gerekir.
Kaç kişinin kullanacağı ve 2 yıl sonraki tahmini büyüklüğü bilgisi ise veritabanı tasarımında kritik rol oynayan sorular. Örneğin veritabanı 2 yıl sonra 5 TB olacak ve aynı anda 50 bin kişi kullanabilecek şeklinde bir bilgi döndü. Eğer veritabanı oluşturma işini default şekilde yaparsanız çok ciddi şekilde performans problemi yaşarsınız. Hatta veritabanı işe yaramaz hala gelir diyebiliriz.
Öncelikle küçük veritabanları için default ayarlarla veritabanı oluşturma işlemiyle başlayalım. Küçüklük büyüklük kavramı değişken bir kavramdır. Ben 500 GB ve altı için default ayarlarla veritabanı oluşturma işlemini gerçekleştiriyorum. 500 GB ve 2 TB arası için kullandığım başka bir tasarım var. 2 TB ve üzerine için kullandığım başka bir tasarım var. Sizinde maksimum performans için aynı şekilde yapmanızı öneririm.
0-500 GB arası boyuta sahip olacak veritabanları için default ayarlarla veritabanı oluşturmak:
SSMS üzerinden Databases sekmesine sağ tıklayıp new database diyoruz. Database Name kısmında veritabanımıza uygulamacılardan gelen talep üzerine bir isim veriyoruz. Owner kısmında veritabanının sahibine ait login bilgisini girebilirsiniz. Eğer veritabanı isteyen kişiye owner seviyesinde yetki vermek istemiyorsanız sa yazıp geçebilirsiniz.
Database name kısmında yazdığınız isme göre kendisi logical name’i belirleyecektir. Initial Size bilgisini ben genelde data file için 512 mb, log file içinse 256 mb olarak belirliyorum. Default olarak burada ilk gelecek rakamlar sizin model veritabanınızı baz alarak gelecektir. Genel de kullandığınız ayarları model veritabanında uygularsanız her seferinde uğraşmanıza gerek kalmaz. “Sistem veritabanları” isimli makalemde detaylı bilgiyi bulabilirsiniz. Autogrowt’un % ayarında kalmaması çok önemli. Örneğin bazı sistemlerde Initial size 5 mb olarak geliyor. Veritabanı oluşturan kişi burada initial size’ı arttırmıyor. Ve auto growth ayarı da %10 olarak geliyor. Log dosyasının autogrowth ayarının bu şekilde yapılmış olduğunu düşünün.
Bunun anlamı şu: Transaction Log dosyasının boyutunun her büyümesi gerektiğinde 5 mb’ın %10’u kadar büyüyecek. Bu şekilde log dosyalarındaki vlf count çok fazla olacaktır ve bu performansı çok ciddi anlamda etkileyecektir. Vlf count nedir ve bu sorun oluşan veritabanlarındaki sorun nasıl düzeltilir sorularının cevaplarını Vlf Count nedir isimli makalemde bulabilirsiniz. Initial Size ve Autogrowth ayarlarını yaptıktan sonra Path kısmından veritabanının mdf uzantılı data dosyasının ve ldf uzantılı log dosyasının nerelerde olacağını belirleyeceğiz.
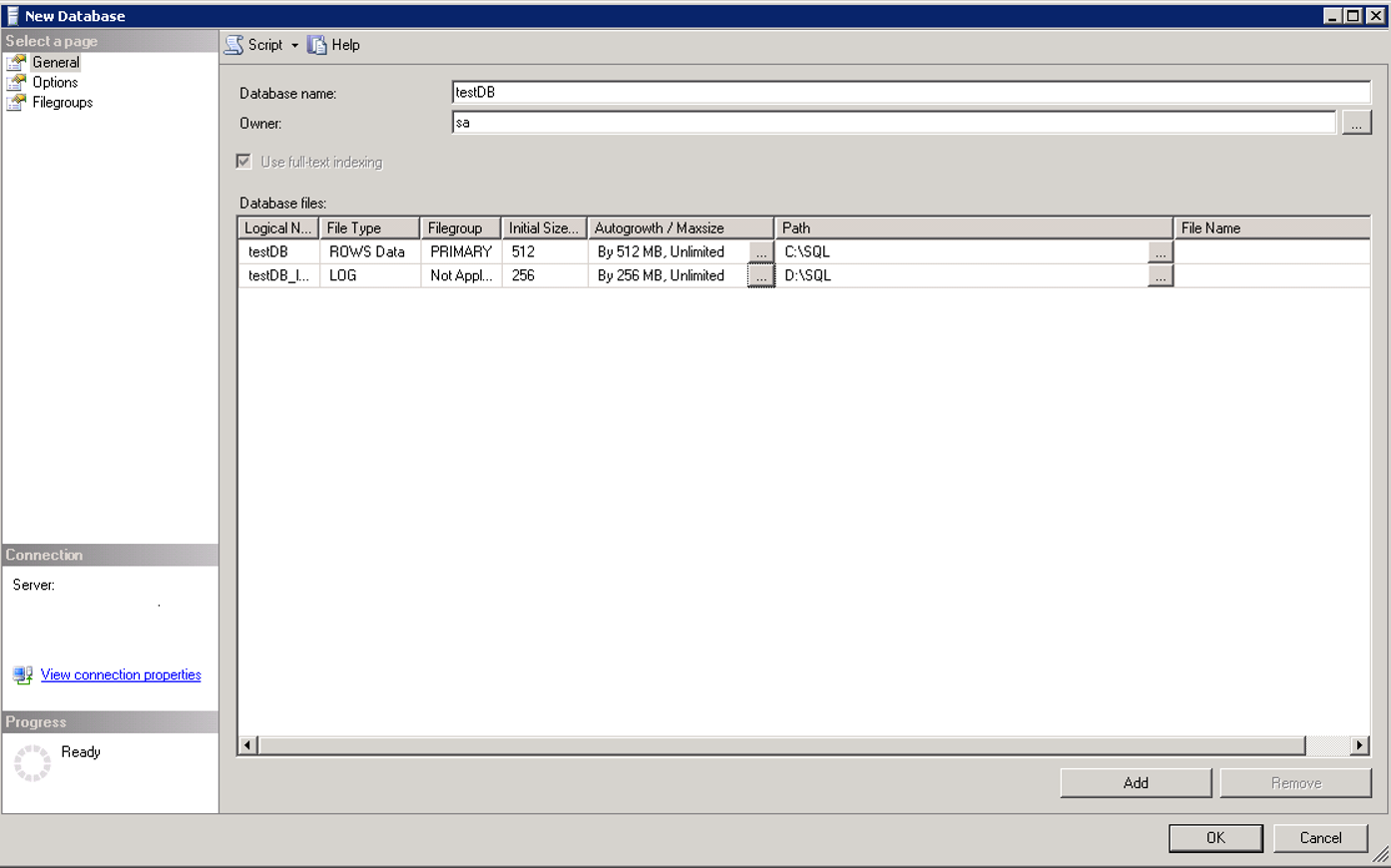
Data dosyalarının ve log dosyalarının farklı disklerde olması performansı arttıracaktır. Hatta imkanınız varsa log dosyasının bulunduğu diskin daha hızlı olması açısından RAID 10 olmasına dikkat edin(“RAID Yapısı” isimli makalemi okumanızı tavsiye ederim). Çünkü data dosyalarını file group’larla ve birden fazla file oluşturma yöntemiyle birden fazla diske yayarak daha fazla IO elde edebiliyorsunuz fakat log file’ı birden fazla sayıda oluştursanız bile aynı anda sadece bir tanesine yazdığı için LOG dosyasına yapılan IO bulunduğu diskin IO hızı ile sınırlı oluyor.(Microsoft’un Log dosyası içinde eş zamanlı yazma özelliği üzerinde çalıştığını duydum.) Hatta imkanınız varsa log dosyanızı SSD’ye koymanızı tavsiye ederim. Tabi ihtiyacınız olup olmadığını bilmeniz çok önemli. Eğer ihtiyacınız yoksa böyle bir maliyete girmek mantıksız olacaktır. Örneğin sorgularınızın bekleme tipi genellikle WRITE LOG ise bu sizin log dosyanızın bulunduğu diskin yavaş çalıştığı anlamına gelecektir. Bekleme Tipleri ile ilgili detaylı bilgiyi Bekleme Türleri ile ilgili makalemde bulabilirsiniz.
500GB – 2TB arası boyuta sahip olacak veritabanları için veritabanı oluşturmak:
Yukarıda anlattığımız gibi veritabanı default olarak primary file group altında primary file’ı kullanarak büyür. Fakat bugüne kadar ki tecrübelerime göre veritabanının boyutu 500 GB’ın üstüne çıktığında tek file üzerinde tek diskin IO kapasitesini kullandığı için performans sorunları yaşamaya başlıyor. Sistem tabloları da primary file group içersinde olduğu için Primary File Group’a yeni file eklemek yerine yeni bir file group oluşturuyoruz ve kaç adet diskimiz varsa bu file group içersinde o kadar file oluşturuyoruz.
Aşağıda göreceğiniz gibi veritabanına sağ tıklayıp properties diyoruz ve file group sekmesinden add file group diyoruz.
Name kısmına file group’umuzun ismini verip ok diyoruz.
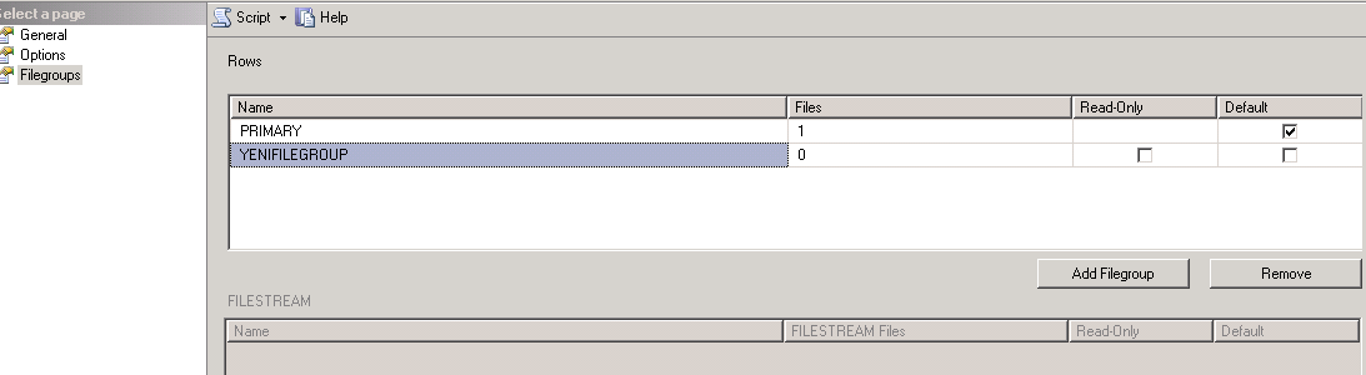
Aşağıdaki gibi bu yeni eklediğimiz file group’un içine yeni file’lar ekliyoruz.
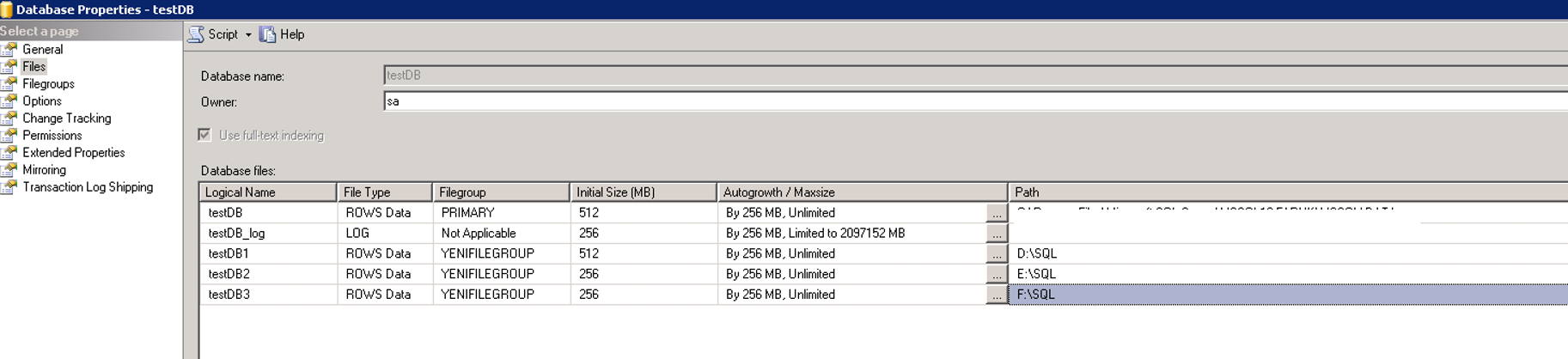
Yeni oluşan tabloların otomatik olarak PRIMARY File Group yerine, yeni oluşturduğumuz file group üzerinde tanımlanmasını istiyorsak file’ları oluşturduktan sonra File group sekmesine geçip defaulf file group olarak yeni oluşturduğumuz file group’u seçiyoruz. 2 TB’a kadar büyüyecek veritabanları için en az 6 tane disk ve en az 6 tane file olmasında fayda var.
Indexler için ayrı bir file group oluşturup bu file group’a da en az 6 disk üzerinde file eklemenizi tavsiye ederim.
2TB tan büyük boyuta sahip olacak veritabanları için veritabanı oluşturmak:
Öncelikle hangi tabloların büyüyeceği talep yapan kişiye sorulur. Örneğin şöyle bir cevap aldınız. Totalde veritabanı boyutu 5 TB olacak. Ve bu 5 TB’ı daha çok şu tablolar oluşturacak.
X Tablosu->1 TB
Y Tablosu-> 700 GB
Z Tablosu->500 GB
K Tablosu->500 GB
L Tablosu->400 GB
M Tablosu->400 GB
Daha sonra bu büyüyecek tabloların partition yapmaya en uygun kolonlarını sormamız gerekiyor. Ve uygulamanın ihtiyacına göre bu tabloları partition yapmamız gerekiyor. Örneğimizde 5 TB veritabanının 3.5 TB’ını yukarıdaki tablolar oluşturuyor. Yukarıdaki tabloların her biri için ayrı file group oluşturup ayrı file’lar tanımlayıp daha sonra her birini partition’da yapabilirsiniz. Hepsi için bir tane file group ve o file group altına file’lar oluşturarak tek bir Partition Schema yapısı ile aynı file group’u da gösterebilirsiniz. Bu tamamen o anki ihtiyaçlara bağlı olarak değişecektir. Partition ile ilgili detayları “Tabloları Partition Yapmak” isimli adlı makalemde bulabilirsiniz.
Örneğin 2 tablomuz çok büyüyecek olsun ve yıllık bazda partition yaptığımızı düşünelim. Her yıl yeni bir filegroup ekleyerek partition’ı bu filegroup’ları kullanacak şekilde güncelliyoruz. Ben çok büyük veritabanları için bu mantıkta çalışıyorum. Aynı veritabanı içersinde file group bazında read_only olarak set edebiliyoruz. Bu şekilde bu iki tabloya sadece bulunduğumuz yıl içersinde read-write, geçmiş yıllara ise sadece read yapılmasını sağlamış olacağız. Yani bu iki tablo için yıllık bazda partititon yapıp her partition’ı da yeni bir file group’a atayıp, geçmiş yıllardaki filegroup ları da read-only yaparsak daha fazla performans elde ederiz ve write yapılmayacak yılların backup’ını almaktan kurtulmuş oluruz. “FileGroup Backup/Restore” isimli makalemi okumanızı tavsiye ederim. Bu şekilde, datalarımızı primary file group’tan ayırmış olmamızın bir avantajını yakalamış oluruz. Tabi bu senaryoda olduğu gibi geçmiş yılları read-only’ye çekemezsek bu avantajı kullanamayız. Ama yinede çok büyüyecek tablolar bir şekilde partition yapılmalı.
Eğer büyüyecek tablolarınız lob veriden(image,video) oluşuyorsa ve verilerin %99 itibariyle 1 MB’tan küçükse veritabanında varbinary olarak saklamak performans açısından daha verimlidir. Verilerin 1 MB’tan büyük olma oranı yüksek olsaydı filestream şeklide tutmak performans anlamında daha iyi olacaktı. “File Stream Nedir ve Nasıl Kullanılır?” isimli makalemi okumanızı tavsiye ederim. Bu makalede sıfırdan veritabanı tasarlamaya değindik. Var olan ve tek file üzerinde çalışan veritabanlarınızı böyle bir yapıya dönüştürmek için daha önce yazmış olduğum aşağıdaki makaleye göz atabilirsiniz.
“Veritabanı file group yapısı ve büyük tablolarımızı başka bir file group’ta yeniden oluşturmak“
Kalan 1.5 TB için bir önceki örneğimizdeki gibi yeni bir file group oluşturup o file group altında file’lar oluşturarak ilerleyebilirsiniz. Daha sonra bu file group’u da default file group olarak set etmeyi unutmayın. Ve uygulamacınızı tablo oluştururken tabloları script’in sonuna “ON defaultfilegroupadınız” ekleyerek defalt file group’unuzda oluşturması gerektiği konusunda uyarın. Ben uyarmama rağmen bazen PRIMARY filegroup’ta oluşturuyorlar. Bu yüzden PRIMARY file group’u 100 MB’ın üstüne çıkamayacak şekilde sınırlıyorum.
Indexler için ayrı bir file group oluşturup bu file group’a da en az 6 disk üzerinde file eklemenizi tavsiye ederim.
![]()